基于忆阻器的存算一体单芯片 清华高滨团队展示1 POPS算力新突破
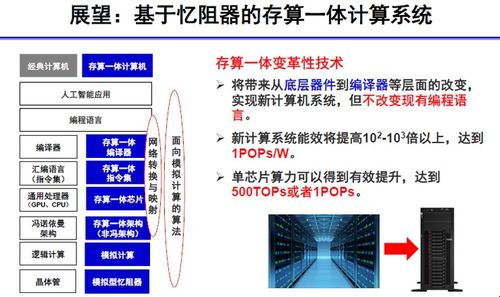
在2020年CCF GAIR(全球人工智能与机器人大会)上,清华大学高滨副教授团队展示了一项前沿研究成果:基于忆阻器(Memristor)的存算一体(Computing-in-Memory)单芯片,其算力潜力可能高达1 POPS(Peta Operations Per Second,每秒千万亿次操作)。这一进展为突破传统冯·诺依曼架构瓶颈、实现下一代高能效人工智能计算提供了极具前景的硬件路径。
传统计算架构中,数据需要在处理器和存储器之间频繁搬运,产生了巨大的能耗和延迟,即所谓的“内存墙”问题。这在处理人工智能,特别是深度学习的海量矩阵乘加运算时,成为提升算力和能效的主要制约。存算一体技术旨在将计算功能直接嵌入存储器单元,在数据存储的位置完成计算,从而极大减少数据搬运,实现能效的飞跃。
忆阻器作为一种新兴的非易失性存储器器件,其电阻值能够随流经的电荷量改变并保持,这一特性天然适合模拟突触的权重,并直接在阵列中执行并行的模拟域乘累加运算。高滨团队的研究正是利用忆阻器交叉阵列,构建了高效的存算一体硬件核心。他们所展示的芯片设计,通过高密度集成的忆阻器阵列和优化的外围电路,能够在单个芯片上实现理论峰值算力达1 POPS的惊人水平。这相当于每秒执行一千万亿次操作,为运行复杂神经网络模型提供了强大的本地化算力支撑。
该技术的意义不仅在于超高的理论算力,更在于其革命性的能效提升。由于减少了大量数据移动能耗,存算一体芯片在执行AI推理任务时,能效比有望比现有GPU、TPU等传统架构高出数个数量级。这对于在边缘设备、物联网终端等对功耗极其敏感的场景中部署复杂AI模型至关重要,有望推动人工智能在更多领域的普及和实时化应用。
在CCF GAIR 2020的报告中,高滨团队也探讨了与此类新型硬件相匹配的人工智能基础软件开发所面临的挑战与机遇。存算一体芯片,尤其是基于模拟计算的忆阻器芯片,其计算范式与数字处理器有根本不同,需要全新的软件工具链、编程模型、算法以及神经网络设计方法。这包括:
- 软硬件协同设计:需要开发编译器、映射工具,将神经网络模型高效地映射到忆阻器交叉阵列的物理结构上,并管理其非理想特性(如器件波动、噪声)。
- 算法与模型适配:设计适合存算一体模拟计算特性的神经网络模型与训练算法,以充分发挥其并行性和能效优势,并克服模拟计算的精度限制。
- 系统集成与优化:探索存算一体核心与现有计算系统(如CPU、数字加速器)的异构集成方案,以及与之配套的数据管理、任务调度等系统级软件。
高滨团队的工作标志着我国在存算一体这一颠覆性计算技术领域已处于国际前沿。将高达1 POPS的潜在单芯片算力从理论推向大规模实用化,仍需在忆阻器器件的一致性、可靠性、大规模集成工艺,以及上文所述的完整软件生态建设上持续攻关。这条道路无疑为应对后摩尔时代挑战、满足未来人工智能对算力与能效的无限渴求,点亮了一盏关键的引路明灯。
如若转载,请注明出处:http://www.gongxiangdaijia.com/product/61.html
更新时间:2026-06-18 10:32:32









